주제
requests와 beautifulsoup를 활용해서 네이버 영화 페이지에 있는 영화 제목들 크롤링해오기
크롤링할 웹사이트 링크
랭킹 : 네이버 영화
영화, 영화인, 예매, 박스오피스 랭킹 정보 제공
movie.naver.com
크롤링
크롤링을 하기 위해서는 2가지를 해야 한다.
1. requests로 링크에 요청을 해서 html을 가져와야 한다.
- requests는 일종의 Ajax 역학을 한다. 일단 requests를 사용하기 위해서는 설치를 해주어야 한다.
2. beautifulsoup을 사용하여 가져온 데이터 안에서 영화 제목들을 가져온다.
- 제목을 쉽게 찾게 해주는 라이브러리
requests 설치
1. Pycharm을 눌러 설정을 들어간다.
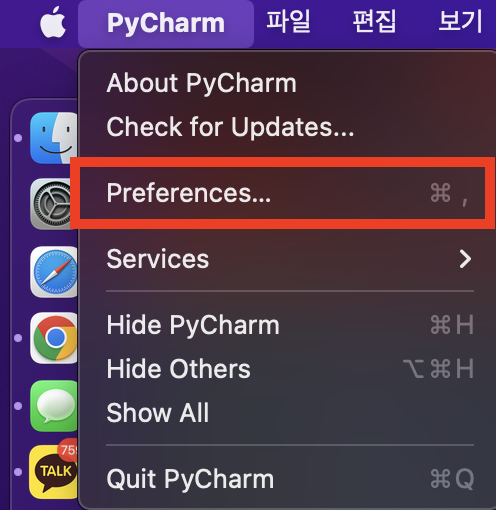
2. 프로젝트에 Python 인터프리터를 누른다.

3. 왼쪽 상단에 있는 +를 누른다

4. requests를 입력하고 하단에 '패키지 설치'를 누른다.

5. 패키지 설치가 완료되면 '성공적으로 설치되었습니다'라는 문구가 하단에 뜬다. 확인을 누르고 끄면 된다.

beautifulsoup 설치
(requests설치와 비슷하여 사진 첨부는 하지 않았습니다.)
1. Pycharm을 눌러 설정을 들어간다
2. 프로젝트에 Python 인터프리터를 누른다.
3. 왼쪽 상단에 있는 +를 누른다
4. 'BS4' 입력하고 설치를 누른 뒤 하단에 '패키지 설치'를 누른다.
5. 패키지 설치가 완료되면 '성공적으로 설치되었습니다'라는 문구가 하단에 뜬다. 확인을 누르고 끄면 된다.
기본 크롤링 코드
import requests
from bs4 import BeautifulSoup
# headers - 코드에서 콜을 날리지만 마치 브라우저에서 콜을 날리는 것처럼 해준다
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
# headers가 여기 끝에 들어가고, 원하는 url을 앞에 적으면 된다
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
print(soup) # print하면 네이버 영화 사이트 html이 출력된다.
beautifulsoup을 사용하여 크롤링하기
1. 네이버 영화 제목에서 우측 마우스를 클릭하여 '검사'를 누른다.

2. DevTools에서 영화 제목이 들어가 있는 링크를 우측 클리하여 '복사'->'selector 복사'를 선택한다.

아래 태그는 현재 네이버 영화에서 1위 하고 있는 영화이다.
<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a>
3. 복사한 태그를 아래에 붙여 넣어준다.
title = soup.select_one('여기 복붙')
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
print(title)
# 출력하면 복사한 태그가 출력
#<a href="/movie/bi/mi/basic.naver?code=186114" title="밥정">밥정</a>
#영화 제목 출력
print(title.txt) #밥정
print(title['href']) #/movie/bi/mi/basic.naver?code=186114
태그 여러 개 선택하는 방법
다른 영화 제목들의 selector을 복사해왔다. 아래와 같이 앞부분과 뒷부분은 같다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
# 같은 앞부분
#old_content > table > tbody > tr
# 같은 뒷부분
#> td.title > div > a
같은 부분만 출력해보면 리스트 형태로 출력되는 것을 알 수 있다. 그리고 영화 순위 사이에 가로 줄이 있다. 중간중간 None이 들어가 있다. 이것은 네이버 영화 사이트에 가로 줄이다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
print(a)
결과
<a href="/movie/bi/mi/basic.naver?code=189027" title="아이즈 온 미 : 더 무비">아이즈 온 미 : 더 무비</a>
<a href="/movie/bi/mi/basic.naver?code=31796" title="반지의 제왕: 왕의 귀환">반지의 제왕: 왕의 귀환</a>
None
<a href="/movie/bi/mi/basic.naver?code=10048" title="죽은 시인의 사회">죽은 시인의 사회</a>
<a href="/movie/bi/mi/basic.naver?code=147092" title="히든 피겨스">히든 피겨스</a>
영화 제목 뽑아오기
None이 아닐 경우 출력하고 마지막에 '.text'를 해줌으로써 영화 제목만 뽑아온다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
movies = soup.select('#old_content > table > tbody > tr')
for movie in movies:
a = movie.select_one('td.title > div > a')
if a is not None:
print(a.text)
결과
밥정
그린 북
가버나움
디지몬 어드벤처 라스트 에볼루션 : 인연
원더
베일리 어게인
먼 훗날 우리
...
'개발 일지 > Web' 카테고리의 다른 글
| [ 스파르타 / Web ] 웹개발 종합반 3주차_#4 (0) | 2022.12.31 |
|---|---|
| [ 스파르타 / Web ] 웹개발 종합반 3주차_#3 (0) | 2022.12.31 |
| [ 스파르타 / Web ] 웹 퍼블리싱 정복 2주차 (0) | 2022.11.14 |
| [ 스파르타 / Web ] 웹 퍼블리싱 정복 1주차 (0) | 2022.11.14 |
| [ 스파르타 / Web ] 웹개발 종합반 3주차_#1 (0) | 2022.11.05 |



댓글